Linux块设备
06 Jan 2017Linux内核 block layer代码分析。
用户空间访问
块设备可以通过块设备文件(/dev/sda1)进行访问,通过设备文件包含的主/从设备号进行标识。主设备号标识设备,从设备号标识分区。
dlw@dlw:linux$ file /dev/sda
/dev/sda: block special (8/0)
dlw@dlw:linux$ file /dev/sda1
/dev/sda1: block special (8/1)
#内核层
块设备的数据以块的方式访问(buffer_head结构体定义).如从设备上读一个文件,文件系统处理程序会将文件偏移转换成块号,然后发出请求加载特定的块。
实际的IO最终由设备驱动完成,块设备层定义了多种不同的处理方法,还提供了设备驱动注册自己的处理方法机制。
内核还会使用电梯算法将请求队列里的IO进行排序,目前包含的算法包括:noop,deadline和cfq。
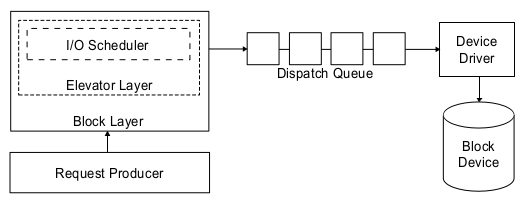
内核块设备系统分为3个部分:
- 通用块层(Block Layer)负责维持一个I/O请求在上层文件系统与底层物理磁盘之间的关系。在通用块层中,通常用一个bio结构体来对应一个I/O请求。
- 调度层(IO Scheduler),核心是电梯算法。传统机械硬盘随机访问性能差,当多个请求提交到设备时,性能很大程度上依赖于请求的顺序。内核汇集IO请求,排序后再调用设备驱动处理。
- 块设备驱动层(Block Driver)需要隐藏硬件特性,提供访问设备的统一APIs。
Block Layer
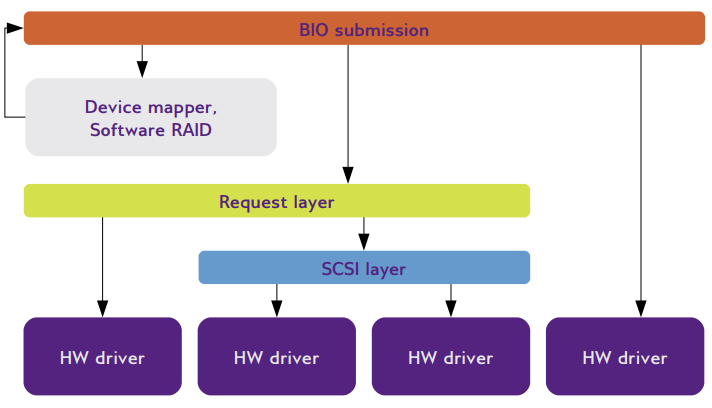
blk-mq
块IO多队列机制(blk-mq, Multi-Queue Block IO Queueing Mechanism)是linux 3.13引入的新块设备层框架,适应SSD等高IOPS低延时设备。 block layer为块驱动提供了两种接口接入系统:request 和make request。
-
- request *接口方式,block layer维护一个简单的队列,新的IO请求提交到队列的末尾,驱动从队列头部收请求。请求放入队列后,block layer有多种处理方式:重新排队最小化seek操作,将小的请求合并成大的操作,公平策略或带宽限制等。由于请求队列由一个锁保护,在大系统中会频繁的在处理器直接bounce,而且数据结构体会经常修改,缓存不友好(cache-unfriendly),使请求队列成为整个系统的瓶颈。
-
- make request *接口方式,做的事情是一致的。但驱动在IO栈的更高层接入,去掉的请求队列,IO请求直接送到驱动处理。这个接口最初不是为高性能驱动设计,而是栈(stacked)驱动(如MD RAID实现)需要将请求发送到真正的底层硬件前先做处理。在其它场景下使用会带来额外代价,所有由block layer完成其它队列处理都不存在,需要在驱动中重新实现。 多队列通过加入第三种接口方式解决这些问题,将请求队列拆分成多个独立的队列:
- 提交队列基于per-CPU或per-node设置。每个CPU提交IO到自己的队列,不需要与其它CPUs交互,这样就可以消除(per-CPU)或减少(per-node)队列的锁。
- 一个或多个硬件分发队列为驱动缓存IO请求。
提交队列中的请求可以按通常的方式操作。对于SSD设备,将请求进行重新排序没有什么作用,并行处理请求却是可以提高性能地。虽然不重排,合并请求可以减少总的IO操作数,提高性能。由于提交队列是在每个CPU上,没有办法将不同队列上的请求进行合并。但可以假设大部分可以合并的请求来自同一进程,它们自然在一个提交队列,所以不能跨CPU合并不是什么大问题。 block layer从提交队列将请求移到硬件队列,可以移动的数量由驱动指定。目前大部分设备只有一个硬件队列,但高端设备可以支持多队列提供并行处理能力。
利用blk-mq结构可以很容易实现高性能的块设备驱动。驱动提供queue_rq()函数处理到达的请求,完成请求后在调用回调函数。具体可以参考null_blk.c的实现。
使用了不同的驱动API和队列模型。
多队列提交路径
- 进程分发到per-cpu软件队列
- 软件队列再映射到硬件issue队列
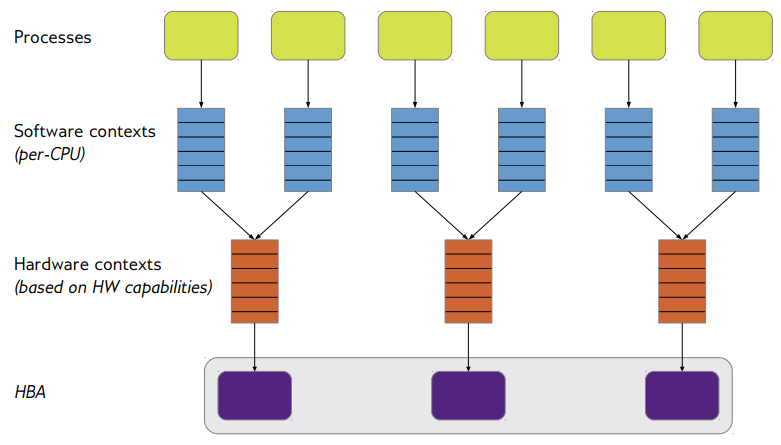
分配请求与标记
- 合并请求分配与标记
- 请求在初始化时分配
- 请求由标记索引(indexed by the tag)
- 标记与分配是合在一起的
- 避免在驱动中分配请求
- 驱动数据在请求后面的剩余空间(slack space)
- 分散聚集(S/G)表是驱动数据的一部分
IO完成
在提交节点使用IPIs完成,避免失效的共享缓存。之前使用的是软中断。
主要数据结构体
** gendisk ** gendisk在内核中表示独立的磁盘,保存了硬盘的信息,重要的字段包括请求队列queue、分区信息part和块设备操作fops。 设备驱动需要分配gendisk结构体,加载分区表,分配请求队列并填充gendisk结构体的其它字段。实际上分区也是由gendisk表示。
gendisk是一个动态分配的结构体,需要专门初始化,不能由驱动自己分配,而是调用alloc_disk()。
struct gendisk *alloc_disk(int minors);
struct gendisk {
struct disk_part_tbl __rcu *part_tbl; /* 分区的指针数组,按分区号索引 */
struct hd_struct part0;
const struct block_device_operations *fops; /* 设备操作 */
struct request_queue *queue; /* 请求队列 */
...
}
** block_device_operations ** 块设备的操作在block_device_operations结构体中定义,注意块设备操作中没有读写,由request()处理。
struct block_device_operations {
int (*open) (struct block_device *, fmode_t);
void (*release) (struct gendisk *, fmode_t);
int (*rw_page)(struct block_device *, sector_t, struct page *, bool);
int (*ioctl) (struct block_device *, fmode_t, unsigned, unsigned long);
int (*compat_ioctl) (struct block_device *, fmode_t, unsigned, unsigned long);
long (*direct_access)(struct block_device *, sector_t, void **, pfn_t *, long);
unsigned int (*check_events) (struct gendisk *disk, unsigned int clearing);
int (*media_changed) (struct gendisk *); /* 废弃,使用check_events()代替 */
void (*unlock_native_capacity) (struct gendisk *);
int (*revalidate_disk) (struct gendisk *);
int (*getgeo)(struct block_device *, struct hd_geometry *);
void (*swap_slot_free_notify) (struct block_device *, unsigned long);
struct module *owner;
const struct pr_ops *pr_ops;
};
struct disk_part_tbl {
struct hd_struct __rcu *last_lookup;
struct hd_struct __rcu *part[];
...
};
** hd_struct ** hd_struct保存硬盘分区的信息。
struct hd_struct {
sector_t start_sect; /* 分区起始扇区 */
sector_t nr_sects; /* 分区结束扇区 */
int partno;
...
}
** block_device ** 内核中表示一个块设备,可以是整个硬盘也可以是一个分区。该结构体只在设备打开时创建。 设备文件第一次打开时,内核分配并填充block_device结构体。实际分配的函数是 bdev_alloc_inode,同时还会在bdev文件系统中分配设备的inode。
struct block_device {
dev_t bd_dev;
struct inode * bd_inode; /* 指向bdev块设备文件系统中的inode,设备以块设备文件的方式访问 */
struct super_block * bd_super;
struct block_device * bd_contains; /* 当表示分区时,bd_contains字段指向分区所在的设备对象 */
struct hd_struct * bd_part; /* 设备的分区结构体 */
struct gendisk * bd_disk; /* 设备的硬盘信息 */
struct request_queue * bd_queue;
struct list_head bd_list;
...
};
** buffer_head ** 表示内存中的数据。以前buffer_head用于映射页面内的一个块,同时也是文件系统和块设备层的IO基本单元。现在使用bio作为IO的基本单元,buffer_head用于描述块映射(通过get_block_t调用),记录页面的统计(通过page_mapping)和封装bio提交保持向后兼容(如submit_bh)。
struct buffer_head {
struct buffer_head *b_this_page; /* 指向同一页面的所有缓冲 */
struct page *b_page; /* the page this bh is mapped to */
sector_t b_blocknr; /* 起始块号 */
char *b_data; /* 指向数据在内存中的位置 */
struct block_device *b_bdev;
bh_end_io_t *b_end_io; /* I/O completion */
};
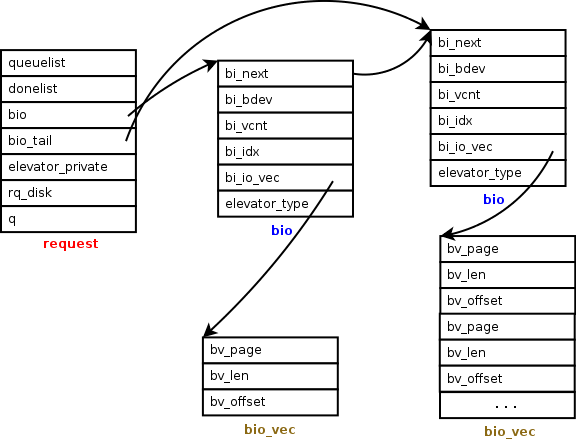
** bio ** bio是块设备层的IO基本单元,表示正在进行块IO操作。当需要从设备上读取一个块时,buffer_head分配一个bio结构体并填充相应字段,然后提交到块设备层。
struct bio {
struct bio *bi_next; /* 请求队列中的下一个bio */
struct block_device *bi_bdev;
struct bio_vec *bi_io_vec; /* 实际的vec数组 */
unsigned short bi_vcnt; /* bio_vec数量 */
struct bio_set *bi_pool;
};
** bio_vec ** 表示内存中IO数据段,bio结构体指向这样的一个段组成的数组。
struct bio_vec {
struct page *bv_page;
unsigned int bv_len;
unsigned int bv_offset;
};
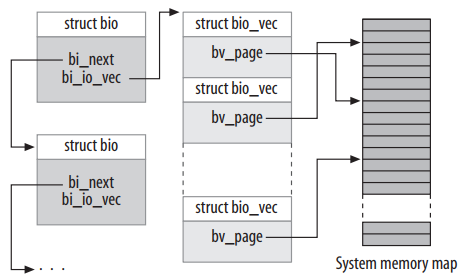
** request ** 挂起(pending)的IO请求,按list的方式在请求队列中保存(按电梯算法排序)。当bio提交到块设备层时,会先尝试加入到请求队列的已有请求中。
struct request {
struct list_head queuelist;
struct request_queue *q;
struct bio *bio;
struct bio *biotail;
struct gendisk *rq_disk;
struct request_list *rl; /* rl this rq is alloced from */
...
};
** request_queue ** 保存挂起的请求和其它用于管理请求队列的信息,如电梯算法。request_fn是设备驱动最重要的处理函数,在真正执行IO时调用。
struct request_queue {
struct list_head queue_head;
struct request *last_merge;
struct elevator_queue *elevator;
struct request_list root_rl;
request_fn_proc *request_fn; /* 处理请求对象 */
make_request_fn *make_request_fn;
prep_rq_fn *prep_rq_fn;
unprep_rq_fn *unprep_rq_fn;
softirq_done_fn *softirq_done_fn;
struct blk_mq_ops *mq_ops;
};
内核操作
设备驱动注册
驱动需要为每个硬盘申请gendisk结构体,并分配请求队列。gendisk结构体用alloc_disk分配,然后通过device_add_disk注册。
打开设备文件
设备可以按普通文件的方式读写。对于设备文件这种特殊文件,文件系统调用init_special_inode设置文件的inode操作为def_blk_fops。当inode被打开后,内核调用文件操作表中的open方法。在def_blk_fops中注册的方法是blkdev_open。
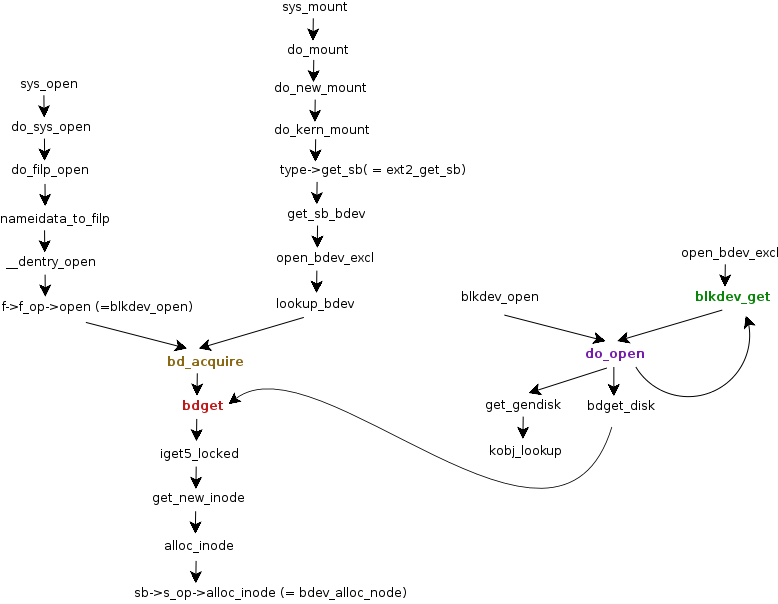 注:图中do_open应该换成__blkdev_get。
注:图中do_open应该换成__blkdev_get。
从上面的调用图可知,内核在mount或open设备的时候,最后都会调用bd_acquire。inode是从块设备文件系统中分配。尽管inode分配函数iget5_locked返回指向inode的指针,在inode结构体之前就已经存在block_device结构体。bdget初始化这个块设备结构体和新的inode结构体。
gendisk和分区信息在__blkdev_get中才填入块设备结构体。
static int __blkdev_get(struct block_device *bdev, fmode_t mode, int for_part)
{
disk = get_gendisk(bdev->bd_dev, &partno);
if (!bdev->bd_openers) {
bdev->bd_disk = disk;
bdev->bd_queue = disk->queue;
bdev->bd_contains = bdev;
if (!partno) {
bdev->bd_part = disk_get_part(disk, partno);
if (disk->fops->open) {
ret = disk->fops->open(bdev, mode);
} else {
struct block_device *whole;
whole = bdget_disk(disk, 0);
ret = __blkdev_get(whole, mode, 1);
bdev->bd_contains = whole;
bdev->bd_part = disk_get_part(disk, partno);
}
} else {
if (bdev->bd_contains == bdev) {
if (bdev->bd_disk->fops->open)
ret = bdev->bd_disk->fops->open(bdev, mode);
}
}
块设备初始化完成后,可以通过分配bio结构体读写数据,然后调用submit_io。
队列处理
块设备驱动的核心是request()函数
** request **
void request(request_queue_t *queue);
请求提交
IO请求通过submit_io提交,bio结构体通过bio_alloc分配。
submit_bh_wbc函数会调用submit_io。
static int submit_bh_wbc(int op, int op_flags, struct buffer_head *bh,
unsigned long bio_flags, struct writeback_control *wbc)
{
struct bio *bio;
bio = bio_alloc(GFP_NOIO, 1);
bio->bi_iter.bi_sector = bh->b_blocknr * (bh->b_size >> 9);
bio->bi_bdev = bh->b_bdev;
bio_add_page(bio, bh->b_page, bh->b_size, bh_offset(bh));
bio->bi_end_io = end_bio_bh_io_sync;
bio->bi_private = bh;
bio->bi_flags |= bio_flags;
guard_bio_eod(op, bio);
if (buffer_meta(bh))
op_flags |= REQ_META;
if (buffer_prio(bh))
op_flags |= REQ_PRIO;
bio_set_op_attrs(bio, op, op_flags);
submit_bio(bio);
blk_queue_make_request定义设备可选的make_request函数。bio结构体传到设备驱动的通常处理方式是先放在请求队列的请求上,队列ready后让设备驱动选择服务的请求。但有些块设备(一般是虚拟设备,如md或lvm)使用请求队列并没有什么作用,最好是将请求直接发给它们,这个就可以通过blk_queue_make_request实现。
162 void blk_queue_make_request(struct request_queue *q, make_request_fn *mfn)
163 {
167 q->nr_requests = BLKDEV_MAX_RQ;
169 q->make_request_fn = mfn;
170 blk_queue_dma_alignment(q, 511);
180 }
2471 void blk_mq_update_nr_hw_queues(struct blk_mq_tag_set *set, int nr_hw_queues)
2472 {
2473 struct request_queue *q;
2487 if (q->nr_hw_queues > 1)
2488 blk_queue_make_request(q, blk_mq_make_request);
2489 else
2490 blk_queue_make_request(q, blk_sq_make_request);
2497 }
blk_mq_make_request将bio加入到请求队列,使用电梯算法检查应该创建新请求还是扩大已有的请求。如果bio可以加入到已有请求。
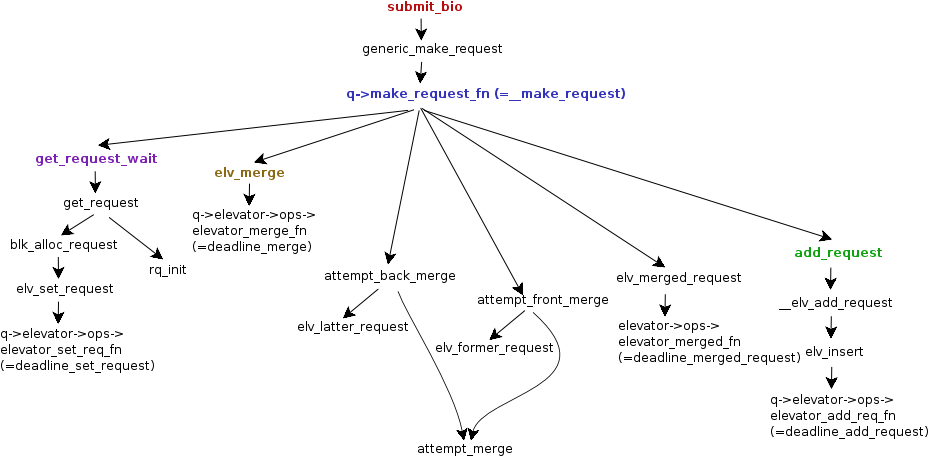
request与bio数据结构体直接的关系:
新请求
电梯算法
请求处理
请求在设备unplugged的时候处理,
访问设备
设备上的数据在内核中以块的方式访问,在用户空间以普通文件的方式读写。用户空间有两种方式读写:对设备发起读写系统调用,或者映射设备文件然后读写内存。内核保证缓存块,所有的代码路径都能使用缓存。
映射IO
每个打开的inode都有一个关联的地址空间对象保存映射信息。
设备文件第一次打开时,bdget函数将inode->i_data的a_ops字段设置为def_blk_aops。这个特殊inode的i_mapping字段指向自己的i_data字段。
readpage的处理方法是blkdev_readpage
static const struct address_space_operations def_blk_aops = {
.readpage = blkdev_readpage,
.readpages = blkdev_readpages,
.writepage = blkdev_writepage,
.write_begin = blkdev_write_begin,
.write_end = blkdev_write_end,
.writepages = blkdev_writepages,
.releasepage = blkdev_releasepage,
.direct_IO = blkdev_direct_IO,
.is_dirty_writeback = buffer_check_dirty_writeback,
};
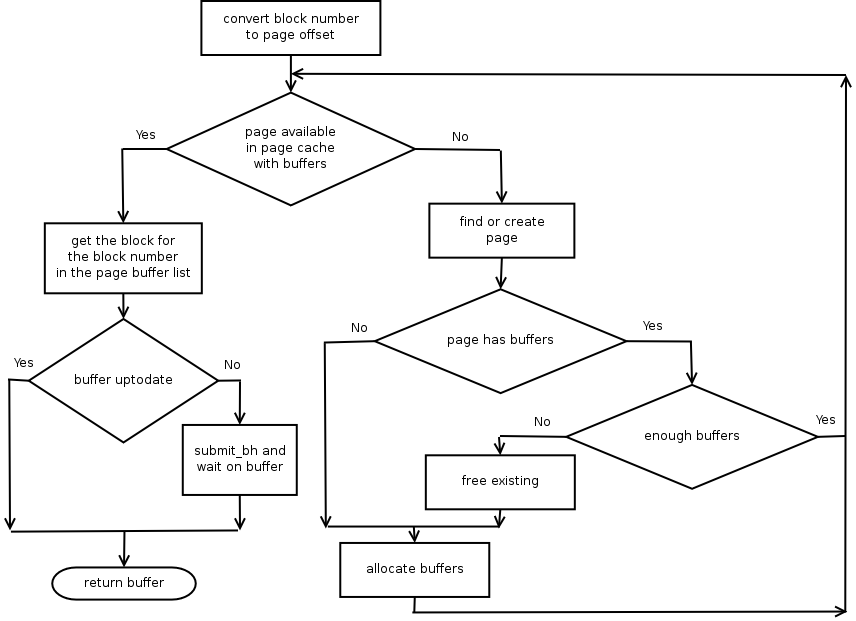
** blkdev_readpage ** 先检查页面是否有最新的相关缓存,如果没有则调用submit_bh。
- 依次检查page对应的每个块是否更新和映射,如果有未更新的块才执行后面的步骤
- get_block
- buffer_uptodate
- buffer_mapped
- 锁定缓存
- 发起IO
- submit_bh,块未更新则重新读取
- end_buffer_async_read,块已更新
系统调用
读写系统调用将任务放在文件操作结构体(file_operations)的处理函数中执行,块设备对于的文件操作通用实现是def_blk_fops(在init_special_inode中设置)。
const struct file_operations def_blk_fops = {
.open = blkdev_open,
.release = blkdev_close,
.llseek = block_llseek,
.read_iter = blkdev_read_iter,
.write_iter = blkdev_write_iter,
.mmap = generic_file_mmap,
.fsync = blkdev_fsync,
.unlocked_ioctl = block_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = compat_blkdev_ioctl,
#endif
.splice_read = generic_file_splice_read,
.splice_write = iter_file_splice_write,
.fallocate = blkdev_fallocate,
};
获取缓存
__bread从设备上读一个块,返回bh。首先检查buffer是否在cache,内核使用页面缓存(page cache)缓存块设备的buffer。从文件(inode)加载的页面数据会缓存起来,然后使用地址空间对象访问,缓存中的页偏移用于定位页。 为了检查块是否在页面缓存中,块号需要转换成inode中的页号。例如,如果块大小为1K,页大小为4K,请求读取的块号为11,则相应的页号为3(每页4个块)。 如果没有找到bh
从缓存中读取buffer的流程图:
Block Driver
块设备驱动以块大小随机访问硬盘,对性能要求严格。
注册
驱动注册
块设备驱动使用注册接口(register_blkdev)让内核可以使用设备。如果没有主设备号则动态分配一个,然后在/proc/devices下创建一个入口。其实调用register_blkdev是可选的。以virtio_blk驱动为例:
virtio_blk驱动模块初始化: ** init() ** ‘drivers/block/virtio_blk.c’
- alloc_workqueue
- register_blkdev,注册块设备驱动,分配主设备号
- register_virtio_driver(&virtio_blk),将virtio_blk注册到virtio驱动框架
static struct virtio_driver virtio_blk = {
.probe = virtblk_probe,
.remove = virtblk_remove,
.config_changed = virtblk_config_changed,
...
};
硬盘注册
内核中gendisk结构体表示硬盘,注册磁盘让系统可以访问主要是对gendisk结构体操作。
** virtblk_probe() **
- vblk->disk = alloc_disk,分配gendisk结构体
- fill tag_set
- blk_mq_alloc_tag_set(&vblk->tag_set)
- vblk->disk->queue = blk_mq_init_queue(&vblk->tag_set)
- device_add_disk
- device_create_file
blk_mq_init_queue分配请求队列。
IO调度
调度器对请求的操作
- 合并,连续扇区请求进行合并
- 排序,基于LBA
- 计时,请求提交的时间
合并
如果一个请求的结束扇区与另一个请求的开始扇区相连,且请求方向一致(读或写),则可以合并(merge)成一个大的请求。合并有两种方式:
- front-merge,新的请求的起始扇区在现有请求之前
- back-merge,新的请求的起始扇区在现有请求之后 请求合并之后,还可能与已有的请求再次组合(coalesce)。如下图中的6与4,5back merge后,可以与7coalesce。
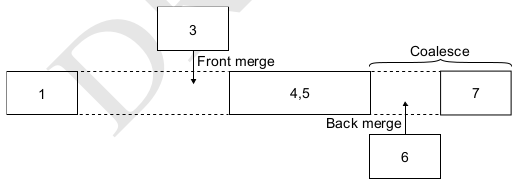
通用elevator层维护了一个用结束扇区号索引的请求哈希表,用于发现back-merge。但没有提供front-merge函数,需要特定调度算法自己实现。 通用elevator层还提供了一个‘one-hit’的缓存(last_merge)保持了最后一次合并的请求。
实现
elevator
struct elevator_type
{
struct elevator_ops ops; /* 由调度算法实现 */
size_t icq_size; /* see iocontext.h */
size_t icq_align; /* ditto */
struct elv_fs_entry *elevator_attrs;
/* managed by elevator core */
char icq_cache_name[ELV_NAME_MAX + 5]; /* elvname + "_io_cq" */
struct list_head list;
};
** elevator_ops **
- elevator_fn,队列中插入一个新请求
- elevator_merge_fn,决定一个新的buffer是否可以与已有的请求合并
- elevator_dequeue_fn,请求从active list取出时调用
elevator_merge_fn *elevator_merge_fn; elevator_merged_fn *elevator_merged_fn; elevator_merge_req_fn *elevator_merge_req_fn; elevator_allow_bio_merge_fn *elevator_allow_bio_merge_fn; elevator_allow_rq_merge_fn *elevator_allow_rq_merge_fn; elevator_bio_merged_fn *elevator_bio_merged_fn; elevator_dispatch_fn *elevator_dispatch_fn; elevator_add_req_fn *elevator_add_req_fn; elevator_activate_req_fn *elevator_activate_req_fn; elevator_deactivate_req_fn *elevator_deactivate_req_fn; elevator_completed_req_fn *elevator_completed_req_fn; elevator_request_list_fn *elevator_former_req_fn; elevator_request_list_fn *elevator_latter_req_fn; elevator_init_icq_fn *elevator_init_icq_fn; /* see iocontext.h */ elevator_exit_icq_fn *elevator_exit_icq_fn; /* ditto */ elevator_set_req_fn *elevator_set_req_fn; elevator_put_req_fn *elevator_put_req_fn; elevator_may_queue_fn *elevator_may_queue_fn; elevator_init_fn *elevator_init_fn; elevator_exit_fn *elevator_exit_fn; elevator_registered_fn *elevator_registered_fn;
调度算法
- noop,实现简单的FIFO,基本的直接合并与排序。Flash设备使用
- anticipatory,延迟I/O请求,进行临界区的优化排序。(Linux 3.0中已废弃)
- deadline,针对anticipatory缺点进行改善,降低延迟时间。数据库等IO密集型应用
- cfq,均匀分配I/O带宽,公平机制。
查看方法
[root@node15 ~]# cat /sys/block/sda/queue/scheduler
[noop] deadline cfq
Noop
Noop(no-operation)调度器仅提供back-merging和有限的coalescing等基本功能。请求用简单的FIFO队列组织,分发的时候,会按扇区排序插入分发队列。
Deadline
Deadline调度器限制请求在队列中的时间基础上最大化全局吞吐量。
Deadline调度器中的请求用两种队列管理:
- sort_list,根据请求扇区号排序的红黑树(red-black tree),用于遍历等待的请求和查找合并机会。读写请求用不同的sort_list保存。
- fifo_list,读写分开的双向链表。 新请求会分别加入到两条队列中,但请求一般是从sort_list队列按扇区顺序批量添加到分发队列,类似于CSCAN算法。fifo_batch连续扇区且相同方向的请求被调度器当作一个单元。一次批量传输(batch)结束的条件:
- 当前数据方向已经没有请求
- 分发的最后一个请求与下一个请求不连续
- 请求数量已达到fifo_batch
Deadline调度器中的每个请求都有一个可配置的超时时间,read_expire和write_expire。fifo_list队列前面的请求超时时,deadline就会把请求分发出去。
- 从当前batch分发
- 选择一个新数据方向。
- 根据选择的数据方向,检查fifo_list队列的超时请求。如果有超时,则发起一个新的batch
Deadline用elevator层提供的扇区排序哈希表进行back-merging,用sort_list发现相连的请求执行front-merging。
struct deadline_data {
struct rb_root sort_list[2]; /* 读写使用独立的 */
struct list_head fifo_list[2];
struct request *next_rq[2]; /* 排序队列中的下一个请求 */
unsigned int batching; /* 连续的请求数量 */
unsigned int starved; /* 读starve写的次数 */
/* 可配置变量 */
int fifo_expire[2];
int fifo_batch;
int writes_starved;
int front_merges;
}
可调参数
| 参数 | 默认值 | 描述 |
|---|---|---|
| read_expire | HZ/2 | 读请求超时 |
| write_expire | 5*HZ | 写请求超时 |
| writes_starved | 2 | 一次写batch前可以进行的读batch次数 |
| fifo_batch | 16 | 每个batch最大请求数 |
| front_merges | 1 | 是否检查front-merge |