NVIDIA vGPU
01 Jan 2024- Overview
- NVIDIA vGPU Software stack
- Deploying NVIDIA vGPU software
- NVIDIA vGPU Schedule policy
- NVIDIA MIG
- NVIDIA Management SDK
Overview
NVIDIA vGPU is a technology that allows a single physical GPU to be shared by multiple virtual machines (VMs) or users. This enables several benefits:
-
Efficiency: Sharing a single GPU among multiple users, instead of each user having their own dedicated GPU, saves hardware costs and reduces energy consumption. This is particularly advantageous in cloud computing environments or large organizations with many users requiring GPU acceleration.
-
Flexibility: vGPU allows users to dynamically access the GPU resources they need, rather than being stuck with a fixed amount of power. This makes it ideal for workloads with varying GPU requirements, such as occasional 3D rendering or machine learning tasks.
-
Scalability: vGPU enables scaling the number of users or VMs utilizing the GPU resources easily. This allows for adapting to changing workload demands without requiring additional hardware investment.
-
Security: vGPU technology isolates each user’s virtual GPU, ensuring privacy and preventing interference between tasks. This is critical for multi-tenant environments where multiple users share the same physical hardware.
There are different vGPU solutions or types offered by NVIDIA, each catering to specific needs:
-
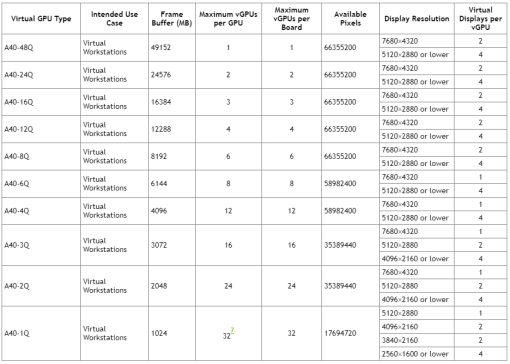
Q-serials, NVIDIA RTX Virtual Workstation (vWS): Designed for high-performance graphics workflows like 3D design, animation, and video editing. Offers dedicated graphics memory and high bandwidth for smooth and responsive experience.
-
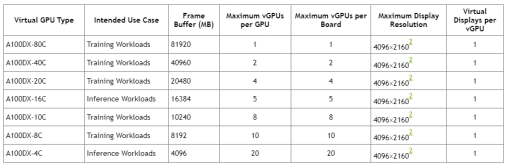
C-serials, NVIDIA Virtual Compute Server (vCS): Ideal for computationally intensive workloads like scientific computing, machine learning, and artificial intelligence. Provides access to the full processing power of the GPU for demanding tasks.
-
B-serials, NVIDIA Virtual PC: Geared towards general-purpose computing with light graphics needs. Enables basic GPU acceleration for tasks like video conferencing, web browsing, and office applications.
Overall, NVIDIA vGPU is a powerful technology that democratizes access to GPU acceleration, making it more affordable and accessible for a wider range of users and applications. However, choosing the right vGPU solution depends on the specific needs and budget of the user or organization.
NVIDIA vGPU Software stack
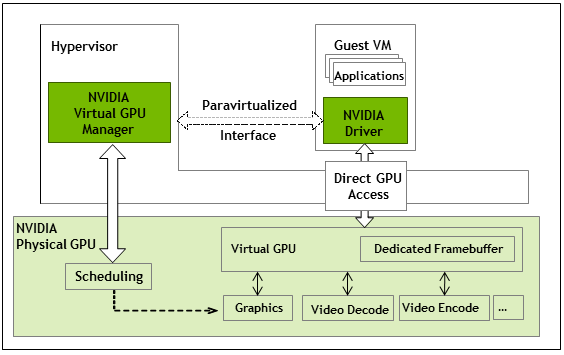
NVIDIA Virtual GPU Manager
NVIDIA Virtual GPU Manager is a key piece of the vGPU puzzle! It sits within the software component of the setup and plays a crucial role in managing and orchestrating the virtualized GPU resources. Here’s a deeper dive into its functionalities:
-
Partitioning: The vGPU Manager efficiently slices the physical GPU’s resources into smaller virtual GPUs (vGPUs) with dedicated memory, processing power, and bandwidth. This allows multiple VMs to share the physical GPU without interfering with each other.
-
Resource Allocation: Based on user needs and workload demands, the Manager dynamically assigns vGPUs to specific VMs. It can also adjust this allocation on the fly, ensuring efficient utilization of the GPU resources.
-
Monitoring and Reporting: The Manager keeps a close eye on the vGPU performance. It provides real-time metrics on workload distribution, resource utilization, and potential bottlenecks. This data helps administrators optimize vGPU configuration and troubleshoot any issues.
-
Security and Isolation: The Manager enforces strict isolation between vGPUs. Each VM only interacts with its assigned vGPU, ensuring data privacy and preventing malware or malicious actors from affecting other users.
-
Management Tools: The Manager comes with a suite of tools for configuring, monitoring, and troubleshooting vGPU deployments. This includes a web-based interface and command-line utilities for easy administration.
The vGPU Manager is available for different hypervisors like VMware vSphere, Microsoft Hyper-V, and Citrix Hypervisor. Its deployment process varies depending on the chosen hypervisor and vGPU solution.
NVIDIA Guest VM Driver
The NVIDIA vGPU Guest VM Driver plays a crucial role in the vGPU experience within the individual virtual machines (VMs). It acts as the bridge between the vGPU assigned to the VM and the applications running within it. Here’s a closer look at its functions and importance:
-
Direct GPU Access: The driver provides low-latency access to the vGPU’s resources for performance-critical workloads like 3D rendering, video editing, and machine learning. It bypasses the overhead of traditional virtualization techniques, maximizing GPU utilization and performance.
-
Communication with vGPU Manager: The driver interacts with the NVIDIA Virtual GPU Manager (vGPU Manager) to request additional resources or report its utilization and performance metrics. This enables dynamic allocation and efficient management of the overall vGPU environment.
-
Compatibility with Applications: The driver ensures compatibility with various GPU-accelerated applications and frameworks. This allows users to leverage the vGPU’s power within their existing workflows without needing application modifications.
-
Operating System Integration: The driver integrates seamlessly with the VM’s operating system, providing a familiar experience for users accustomed to working with physical GPUs. It handles tasks like memory management and resource contention within the guest VM.
Importance of the Guest VM Driver:
Smooth and Responsiveness: The optimized access to the vGPU resources ensures smooth and responsive performance for GPU-intensive workloads within the VM. This translates to a better user experience for tasks like animation rendering or real-time simulations.
Efficient Resource Utilization: The driver enables efficient communication with the vGPU Manager, allowing for dynamic allocation of resources based on the VM’s actual needs. This optimizes utilization of the physical GPU and prevents wasted resources.
Compatibility and Flexibility: The driver’s compatibility with various applications and operating systems provides flexibility for users. They can leverage the vGPU’s power for different types of workloads without needing specific software adaptations.
Choosing the Right Driver:
It’s essential to choose the correct NVIDIA vGPU Guest VM Driver for your specific setup. Factors to consider include:
Operating System: Ensure the driver is compatible with the VM’s operating system.
vGPU Model: Choose the driver specifically designed for the physical GPU model used in your vGPU setup.
vGPU Manager Version: The driver must be compatible with the version of the vGPU Manager running in your environment.
NVIDIA License System
NVIDIA vGPU License System acts as a central hub for managing NVIDIA vGPU software licenses. This includes tasks like creating license servers, allocating licenses to vGPU deployments, and monitoring license usage. Administrators can manage licenses for all vGPU deployments from a single interface, simplifying administration and ensuring consistent policies across the organization.
The system utilizes a pool of “floating” licenses, meaning a single license can be dynamically assigned to different VMs as needed. This optimizes license utilization and reduces costs compared to assigning dedicated licenses to each VM.
Management SDK
NVIDIA vGPU Management SDK offers programmatic access to detailed information about physical and virtual GPUs in your vGPU environment. This includes metrics like resource utilization, performance counters, error codes, and configuration settings. Developers can build custom applications for monitoring vGPU performance, resource usage, and health. This allows for proactive identification of potential issues and optimization of vGPU workloads. The SDK can be integrated with existing monitoring and management tools, providing a holistic view of the vGPU environment and simplifying its administration.
Components of the NVIDIA vGPU Management SDK:
-
NVML Library: This core library provides functions for querying and manipulating vGPU information. It supports both local and remote access to vGPUs, enabling management from a centralized location.
-
nvml_grid.h Header File: This header file defines functions specific to managing vGPUs in a vGPU environment. It allows developers to control aspects like vGPU allocation, migration, and resource sharing.
-
Management SDK User Guide: This comprehensive guide provides detailed information about the SDK’s functionality, API calls, and examples.
Deploying NVIDIA vGPU software
Here’s a breakdown of the key steps involved:
Preparation
Determine your needs: Identify the type of workloads you want to accelerate with vGPU (graphics, compute, etc.) and the number of users requiring access.
Choose your software: Opt for NVIDIA RTX Virtual Workstation (vWS) for high-performance graphics, NVIDIA Virtual Compute Server (vCS) for compute-intensive tasks, or NVIDIA Virtual PC for basic graphics needs.
Select your hypervisor: Ensure your chosen hypervisor is compatible with NVIDIA vGPU software. Popular options include VMware vSphere, Microsoft Hyper-V, and Citrix Hypervisor.
Prepare your hardware: Choose a server platform with enough processing power and RAM to handle the vGPU workload efficiently. Check NVIDIA’s validated server platform list for recommendations.
Installation
Download the software: Access the NVIDIA Licensing Portal and download the vGPU software package for your chosen hypervisor and software version.
Install the vGPU software: Follow the installation instructions provided by NVIDIA for your specific hypervisor environment. This typically involves installing drivers, libraries, and management tools. Here is a example of install NVIDIA vGPU software on Linux KVM platform.
- change the gpu work mode with
gpumodeswitchtool - install vgpu manager
NVIDIA-Linux-x86_64-510.47.03-vgpu-kvm.run - enable SR-IOV for Ampere or Hooper
- config MIG (optional)
- init vgpu types and create vgpu instances
- create VM
- install grid driver in VM
511.65_grid_win10_win11_server2016_server2019_server2022_64bit_international.exe - config licserver (/etc/nvidia/gridd.conf) and start nvidia-gridd service
- install Cuda driver and run the demo test
NVIDIA vGPU Schedule policy
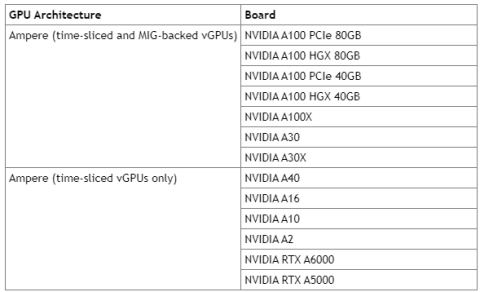
NVIDIA Ampere GPU support time-sliced and MIG-backed vGPUs.
Time-sliced Scheduling
Time-sliced scheduling allows multiple virtual GPUs (vGPUs) to share the resources of a single physical GPU in a time-division multiplexing manner. Each vGPU gets a dedicated time slice to execute its tasks on the GPU, with vGPUs taking turns accessing the GPU’s resources.
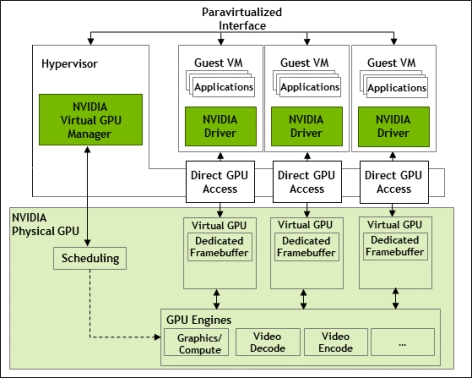
Time-sliced schedulers
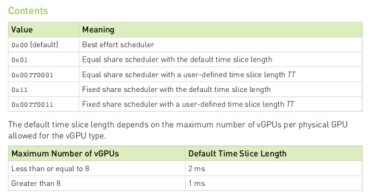
There are 3 types of schedulers
-
Best effort scheduler (default), aims to provide all virtual machines (VMs) with equal access to a shared physical GPU. It does this by dynamically allocating GPU processing cycles to each vGPU based on its current demand. This means that a vGPU with a more demanding workload will receive more processing cycles than a vGPU with a less demanding workload. The best effort scheduler is the default scheduler for all NVIDIA GPUs that support vGPUs. It is a good choice for environments where there is a mix of workloads with varying CPU and GPU demands. However, it is not the best choice for environments where consistent performance is required for all VMs.
-
Equal share scheduler, ensures that each vGPU gets an equal portion of the GPU’s processing cycles over a specific period, regardless of their workloads. Each vGPU gets a guaranteed minimum amount of resources, leading to consistent performance even under varying workloads.
-
Fixed share scheduler, each vGPU permanently receives a predefined number of slices, determined by its type.
The rate at which vGPUs are switched on the GPU is determined by a configurable scheduling frequency (default: 480 Hz for less than 8 vGPUs, 960 Hz for 8 or more).
Pros:
-
Efficient resource utilization: Maximizes GPU usage by sharing it among multiple VMs, potentially reducing hardware costs.
-
Scalability: Enables more users or VMs to leverage GPU acceleration without adding physical GPUs.
Cons:
-
Potential performance impacts: Frequent context switching between vGPUs can introduce overhead, which might affect performance-sensitive workloads, especially if multiple vGPUs are actively competing for resources.
-
Unpredictability: The actual performance experienced by each vGPU can vary depending on the number of active vGPUs and their workloads, making it less suitable for workloads with strict latency requirements.
Best uses for time-sliced scheduling:
General-purpose workloads: Users with less demanding GPU needs, such as office productivity, web browsing, or light graphics tasks.
Cost-sensitive scenarios: Organizations prioritizing hardware cost savings and maximizing GPU utilization.
NVIDIA vGPU mig-backend Scheduling
Leverages Multi-Instance GPU (MIG) technology to physically partition a single NVIDIA A100 GPU into multiple isolated GPU Instances (GIs). Each GI has its own dedicated compute, memory, and cache resources, ensuring predictable performance and isolation. Reduces interference and security risks between tenants by isolating workloads within GIs. Ideal for compute-intensive workloads like AI, machine learning, data analytics, and scientific computing.
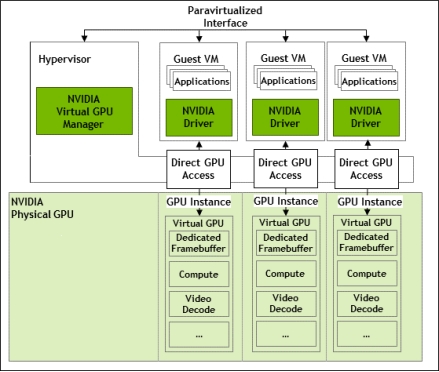
Scheduling Mechanism:
-
GI-Level Scheduling: Tasks are scheduled at the granularity of GIs, not individual vGPUs.
-
Workload-Based Allocation: GIs are dynamically allocated to VMs based on workload demands, ensuring optimal utilization of GPU resources.
-
Fine-Grained Control: Administrators can fine-tune scheduling policies and resource allocation to prioritize specific workloads or users as needed.
Benefits:
-
Improved Performance: Less overhead compared to time-sliced scheduling, leading to better performance and lower latency for compute workloads.
-
Increased Efficiency: More efficient utilization of GPU hardware resources through spatial partitioning.
-
Enhanced Isolation: Improved security and isolation between workloads, making it suitable for multi-tenant environments.
-
Flexibility: Allows for different vGPU profiles and scheduling policies to be applied to different GIs, enabling customization for specific workload needs.
Best Uses:
Compute-Intensive Workloads: AI, machine learning, deep learning training and inference, data analytics, scientific computing, and high-performance computing (HPC) applications.
Multi-Tenant Environments: Cloud service providers or organizations sharing GPU resources among multiple users or tenants.
Workloads Requiring Isolation: Sensitive workloads with strict security or performance isolation requirements.
Considerations:
GPU Compatibility: MIG and mig-backend scheduling are only available on select NVIDIA GPUs with MIG support (currently A100 and some newer models).
Workload Suitability: Not optimal for graphics-intensive workloads or those heavily reliant on GPU memory bandwidth, as MIG can introduce some memory bandwidth limitations.
Management Complexity: Requires understanding of MIG technology and careful configuration to ensure optimal performance and resource allocation.
In summary, mig-backend scheduling offers a powerful approach for maximizing GPU utilization and performance for compute-intensive workloads in virtualized environments, while providing enhanced isolation and security.
NVIDIA MIG
NVIDIA Multi-Instance GPU (MIG) is a technology that allows a single physical GPU to be partitioned into multiple virtual GPUs (vGPUs). This enables multiple users or applications to share a single GPU, while each instance has its own dedicated resources, including memory, compute cores, and bandwidth.
MIG is available on NVIDIA Ampere and Hooper GPUs.
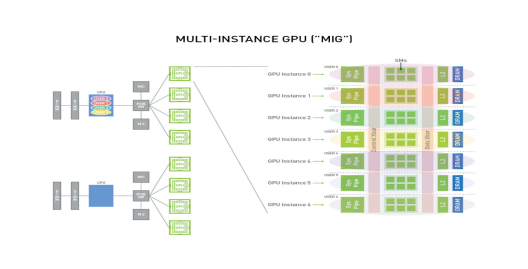
-
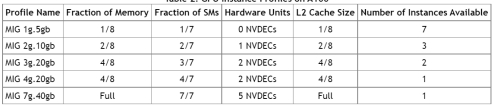
GPU Memory/SM Slice,内存和SM最小分配单元(fraction),1/8内存资源,1/7 SMs
-
GPU Instance(GI),GPU slices和GPU engines(DMAs, NVDECs…)的组合
MIG can be deployed on bare matel, GPU passthrough and vGPU.

NVIDIA MIG - CUDA
Set MIG mode
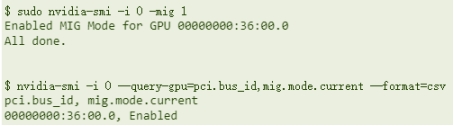
Create MIG GI instance with a specified type

Create CI instance [optional]
Specify the MIG device running the CUDA program

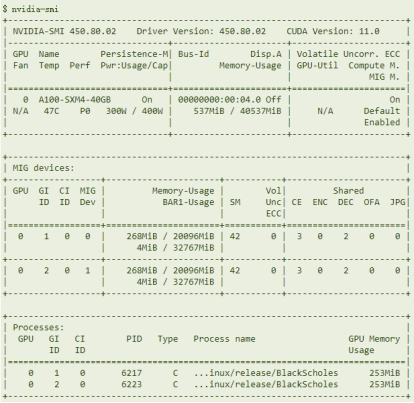
NVIDIA MIG - vGPU
enable SRIOV

Set MIG mode
Create MIG GI instance with a specified type
Create vGPU device through mdev interface
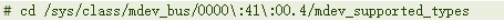

Add vGPU device to virtual machine configuration
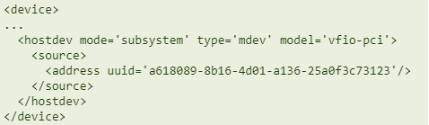

Install vGPU Guest Driver in the virtual machine
Create CI instance
Run CUDA program
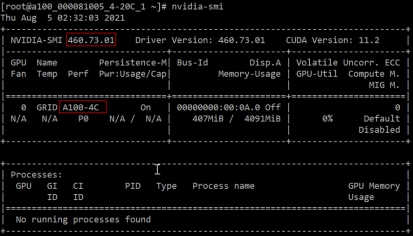
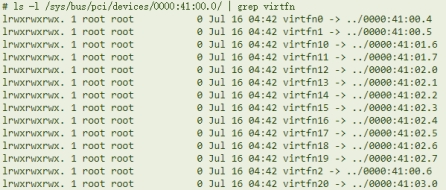
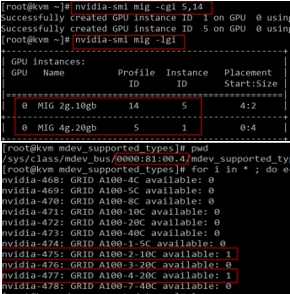
Each vGPU instance occupies one VF (time-slice mode also applies)
Total VF(16) > max instance(10)
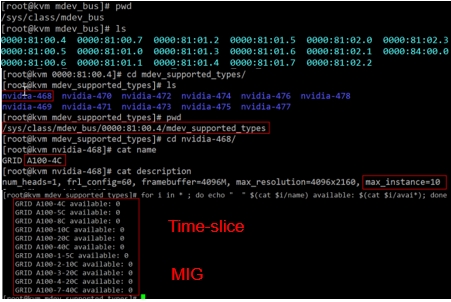
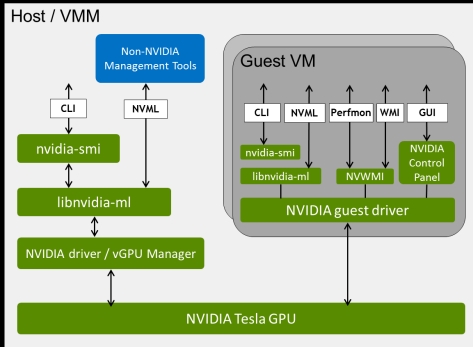
NVIDIA Management SDK
NVIDIA vGPU Management SDK, a powerful tool for developers who want to build custom applications for monitoring and managing NVIDIA vGPU deployments.
-
nvidia-smi, a powerful command-line tool for monitoring and managing NVIDIA GPUs on Linux and Windows systems. It provides a wealth of information about your GPU.
-
NVML(NVIDIA Management Library): This core library provides functions for querying and manipulating vGPU information. It allows access to detailed metrics like resource utilization, performance counters, error codes, and configuration settings. You can utilize it for:
Monitoring GPU usage and health of individual vGPUs and the overall vGPU environment.
Identifying potential performance bottlenecks and resource contention issues.
Optimizing vGPU allocation and configuration to maximize performance and utilization.
-
NVIDIA Control Panel, a powerful software tool that allows you to fine-tune the settings of your NVIDIA graphics card and improve your overall PC experience. Key features includes display management, 3D settings, video settings.
-
NVWMI(NVIDIA Enterprise Management Toolkit), a software tool that allows developers and system administrators to manage and monitor NVIDIA GPUs. It provides access to a wealth of information about the GPU, including:
- Performance counters: These track the GPU’s utilization, temperature, memory usage, and other metrics. You can use this data to monitor the health of the GPU and identify potential bottlenecks.
- Configuration settings: You can use NVWMI to query and adjust various GPU settings, such as clock speeds, power limits, and fan speeds.
- GPU information: NVWMI provides detailed information about the GPU, such as its model, BIOS version, and driver version.